Blog Archives
Resiliencia de redes
Mantener la red en funcionamiento, siempre
La resiliencia de red es la capacidad de proporcionar y mantener un nivel de servicio aceptable ante fallas que supongan un reto para las operaciones normales. Más que mejorar el tiempo de actividad o crear redundancia, la resiliencia de red incorpora una capa de inteligencia a la columna vertebral de una empresa: la infraestructura de TI.
En una encuesta independiente realizada a líderes de TI, el 49 % señaló que la resiliencia de la red era prioritaria.
Para garantizar el máximo tiempo de actividad, las empresas necesitan una solución integral diseñada para proporcionar los niveles más altos de continuidad del negocio a través del monitoreo y soluciónes proactivas.
Para obtener más información sobre cómo garantizar la resiliencia de la red para su empresa, descargue nuestro informe técnico ahora.
Redundante no es lo mismo que Resiliente
La redundancia es una parte importante del rompecabezas y la confiabilidad de un centro de datos depende en gran medida de generadores de reserva, hardware de repuesto disponible y conexiones de red secundarias. Pero si bien la redundancia es una parte de la solución de resiliencia, no es la única consideración. En ubicaciones más pequeñas y oficinas satélite, no es rentable incorporar redundancia. Y sin personal técnico en el sitio, la capacidad de supervisar, gestionar y reparar la infraestructura informática de forma remota es una adición importante a una solución resiliente.
La gestión de Smart Out-of-Band le permite al equipo de ingeniería de redes acceder de forma segura a dispositivos críticos desde una ubicación central, para anticipar los problemas y solucionarlos sin desplazar a un técnico al sitio.
Descubra los problemas de redes que preocupan a los tomadores de decisiones de TI. Lea la investigación independiente encargada por Opengear.
")
La nueva plataforma de resiliencia de redes
La plataforma de resiliencia de redes de Opengear se basa en la presencia y proximidad de un servidor de consola NetOps o Smart OOB Servidor de consola en cada ubicación informática, gestionados de forma central a través del software de administración Lighthouse.
La plataforma de resiliencia de red proporciona acceso remoto y seguro a los dispositivos de red críticos mediante un plano de gestión independiente, con la capacidad de automatizar los procesos de NetOps, como implementar y aprovisionar equipos de forma segura, y el acceso a dispositivos IP remotos en cualquier ubicación periférica.
Esta plataforma es La Red de los ingenieros de redes. Un acceso remoto seguro, a través de hardware físico en cada ubicación, que proporciona una red independiente siempre disponible y abierta solo para el personal de TI, para ser utilizada en implementaciones del primer día, para la gestión diaria y durante eventos en red de producción.
La tecnología Smart Out-of-Band de Opengear, conjuntamente con el uso de herramientas de automatización NetOps de arquitectura abierta (compatibilidad con Docker, entorno de ejecución de Python), proporciona acceso seguro a los puertos de consola al mismo tiempo que crea un plano de gestión sólido.
Programe una demostración para obtener más información sobre nuestra plataforma de resiliencia de redes

Opengear’s Resilient Online Connectivity Enables Research on the Ocean Floor
The Challenge
Nestled on the floor of the of the Pacific Ocean, three miles below the surface, is the ALOHA Cabled Observatory (ACO). Providing real-time oceanographic data, it is used by scientists all over the world, enabling them to conduct experiments under the water – where maintaining a high reliability network connection is critical.
The solution had to meet several criteria:
- Maintain a flexible and extensible network solution able to adapt to the ACO’s future needs
- Provide secure connections to control equipment on the ocean floor
- Stream terabytes of data over a submarine fiber optic cable reliably
- Ensure resilient connectivity keeping ACO online to collect and transmit data
The Opengear Solution
ACO chose Opengear to provide secure access and resilience. Opengear devices were placed at the AT&T Cable Landing Station on Oahu. Connecting ACO to land by a 147 mile long submarine fiber optic cable that enters through the station, the network equipment manages ACO’s power supply and communications. It also forwards data streams through the University of Hawaii to its Manoa campus.
To provide secure access, Opengear safeguards the connection between the landing station and the data center through an IPsec VPN tunnel. This enables Opengear devices in the data center to contact the station and control resources at the ACO with secure remote access to equipment at the ACO, established from anywhere using an integrated SSL VPN. This ensures that the scientists can easily conduct experiments and maintain security compliance while complying with Federal Information Processing standards. Using Opengear devices, the ACO is also surpassing the Department of Defense requirements for securing unclassified data.
To ensure resilience of ACO sensors, Opengear provides both in-band and Out-of-Band (OOB) control for streaming hydrophone and video data through a high availability failover pair technology of encrypted connections from the AT&T Cable Landing Station to one of the School of Ocean and Earth Science Technology’s (SOEST) data centers.
Opengear’s highly extensible and reliable solution provides resilient connectivity. That with secure access, versatile data management and redundant data storage enables them to plan for future upgrades. Opengear devices safeguard the availability of the underwater connection and the uptime of its land based network and data.
“We’ve all heard of the ‘deep web’, but maintaining the deepest reach of the internet – beneath three miles of water – represents an exciting new frontier and offers a uniquely insightful perspective as we work to better understand our oceans and our planet. We thank Opengear for providing dependable networking solutions for our forays into this underwater frontier.”
– Brian Chee, IT Specialist, University of Hawaii at Manoa
Opengear’s Smart Out-of-Band and redundant failover to cellular technology enables the coordination of computers and devices to offer real time data management. It also helps them achieve redundant copies of all datasets transmitted by the ACO that are stored at different physical locations to ensure safety from disaster.
Aloha Cabled Observatory’s need has been fulfilled and now:
- Has a high availability connection that ensures secure access to equipment at the ocean floor
- Can support future expansion of its equipment and capabilities
- Streams terabytes of data for availability in real time and are redundantly stored at different locations to safeguard against data loss
Scientific Research Customer
The ALOHA Cabled Observatory (ACO) sits on the ocean’s floor, three miles below the water’s surface and sixty miles north of the Hawaiian island of Oahu. The observatory provides real-time oceanographic data using equipment including a hydrophone and pressure sensor, along with instruments for measuring and communicating temperature, salinity, currents, acoustics, and video images. The ACO holds several records associated with its depth: it is the deepest functioning observatory of its kind, the deepest power node on earth, and the deepest extent of the Internet. The data captured and transmitted by these instruments is available to scientists and the public online in real-time.
Keeping i3D.NET Undefeated By Downtime
Opengear Solutions for Network Resilience
Ensuring network resilience is an important business priority for i3D.net. To maintain its global operation, i3D.net runs a complex low-latency network, with thousands of servers spread over more than 35 points of presence on 6 continents.
It is key that this network is kept up and running at all times. As Rick Sloot, chief operations officer, i3D.net explains: “Ten years ago, this was very difficult to achieve. There were very few ways of handling and managing your servers when the internet went down and those that were available were expensive and did not work well. As technology has advanced over the past decade, customer expectations have grown in line, and a high level of network resilience is now demanded by our users.”
“As we expanded as a business, opening up new locations around the world, it was becoming increasingly difficult to find a vendor capable of delivering a reliable way of keeping us up and running at all times, across all our locations.” continued Sloot.

“We struggled to find local vendors who could support us. Often, we weren’t able to pinpoint the issue or access the faulty equipment. We needed to find a way of managing equipment remotely, identifying and resolving the problem, while keeping the network online. “We started to look for a vendor who could work with cellular technologies such as 4G and who could deliver out-of-band management. Opengear fitted the bill perfectly. Opengear’s tools can support 4G cellular out-of-band connections in all our global locations which have enabled us to save time and money. We were looking for a partner that could deliver triple-A equipment on time all over the globe and knew we could rely on Opengear for this.”
i3D.net decided to work in partnership with Opengear and implement its ACM 7008-2-L Resilience Gateway to provide smart out-of-band management to its entire IT infrastructure, and also to provide a built-in backup LAN and/ or backup Internet connectivity option for all their remote sites.
Reaping the Rewards
Today, i3D.net uses the Opengear Resilience Gateway as a fall-back, providing out-of-band management, as and when required, to its routers all over the world. It has achieved a raft of benefits as a result. For example, it has helped to significantly streamline the process of bringing new sites online.
In the past, when i3D.net had to carry out a deployment outside the Netherlands, a technical operations engineer flew to the location and installed the new switches but would typically struggle to configure them. Today, i3D.net simply connects the Opengear Resilience Gateways to these network switches and its network operations engineers back in the Netherlands are then able to configure the whole site remotely via the Opengear device. “This is very powerful and a huge benefit for us in terms of the time and costs saved not only in provisioning but also ongoing maintenance” commented Sloot.
“We were looking for a partner that could deliver triple-A equipment on time all over the globe and knew we could rely on Opengear for this.”
Using Opengear Resilience Gateways also allows i3D.net to stay one step ahead of any pending network failures. According to Sloot: “We don’t like downtime and neither do our customers. Today, if there is an issue, we can directly connect to our routers anywhere in the world without having to wait for someone at the locations to access and fix it. The agility of the Opengear solutions means we can quickly help our customers and maintain our high standards as a performance hosting company.”

Looking Ahead
Today, i3D.net continues to expand and open global locations dynamically. It is also in the process of switching to a new Juniper Networks router platform. As Sloot explains: “This will give us the opportunity to launch our Global Low-latency Anti-DDoS solution (GLAD). Every region where we are changing the router and do not have an Opengear Resilience Gateway will now receive one.
“Finally, we have an enterprise customer for which we are remotely managing servers, running routers and firewalls in their own environment. We are planning to place the Opengear solution there. It marks the first time we have carried out a deployment of Opengear’s Resilience Gateway outside our own data centres.”
The rapidly expanding use of Opengear at i3D.net bears witness to the broad benefits it brings the hosting provider and also highlights a partnership that goes from strength to strength today and will look to evolve further in the future. i3D.net is on a fast growth path and Opengear continues to support its dynamic expansion worldwide.
Hosting Company
i3D.net is a leading provider of high-performance hosting and global infrastructure services. The company notably excels in-game hosting and infrastructure, serving 100 million gamers daily for game publishers and independent developers on consoles, PC and mobile. The i3D.net network is one of the world’s top-10 most connected hosting provider networks. i3D.net is now a Ubisoft company, having been bought by the French publisher in 2018.
Living on the Edge Podcast: with Roy Chua of AvidThink
Transcipt
Steve:
Today, we’re talking with Roy Chua, founder and principal at AvidThink, which is an independent research firm focused on infrastructure technologies, including IOT, SD-WAN, SDN, and of course The Edge.
Roy, first of all, thanks for joining the podcast and sharing your views from The Edge.
Roy:
You are very welcome, and thank you for having me Steve.
Steve:
I know you started out in various engineering and product roles within networking. Could you just describe briefly how you went from being someone who was in front of the rack to now looking out across the industry trends?
Roy:
Yeah, I definitely can. Too long ago, very long ago, once upon a time, I started my networking career at Cisco actually, and I was actually inside the rack because I was writing firmware. I was writing firmware to bring up a new ATM where an ATM in networking stood for asynchronous transfer mode in that ancient times. And I thought it was going to be one of the hottest technologies, but it didn’t quite pan out that way, but I was writing firmware on Cisco’s ATM interface processor, the AIP on the Cisco 7000 router for a new interface.
Anyway, that’s how I got my start in networking. And obviously I started the same way many network engineers did. Doing a lot of testing and lab work and stuff with different protocols. And IP wasn’t the only protocol back then. We still had to learn DECnet and AppleTalk and IPX/SPX, and other protocols like that. So it was truly internet working.
But anyway, what happened after that, as I stayed in networking and the network storage space for some time moving from engineering into the field, and then into product management, and I also did a stint at a dotcom, like many others, and along the way, worked for different companies, help found a few companies. One was in network testing, and that evolved into a product that was eventually acquired by Spirent Communications, Layer 4-7 testing, and so I got to know a lot of network equipment in that job. And the other one in network identity management and authentication. And that, that company I founded in, in 2004, and unfortunately in 2008 after we had raised $26 million we couldn’t get our series to C close because Lehman Brothers had collapsed, the market had collapsed and it was unfortunate. But I stayed around after the assets were sold off, to attempt to buy it back. And I failed to do that. I was trying to get back my company. But in that process, I took on consulting – VP of marketing, VP of products positions – and eventually I teamed up with a friend and we started SDxCentral back in 2012 and, and SDxCentral had two lines of business. It was originally called SDN Central – software defined networking. It was very, very early. This was back in 2012, February when we launched the site.
We have two main lines of business, one in the media news which is very well known and the other in research and analysis. And we started publishing reports at the end of 2013 on SDN and network virtualization. So it was quite early in the space and then many years later, and many, many, many reports later in the end of 2018, we spun the research group out of SDxCentral into an independent company, which is AvidThink while the media news side stayed with SDxCentral.
And so, here I am, running a small boutique research firm that covers the same infrastructure technologies that I started my career with.
Steve:
Perfect. Thanks for running through the progression. I think everybody has a 2008 story that they may or may not want to tell. Nice to hear that yours got you moving in the right direction.
Roy:
Exactly.
Steve:
So you mentioned SDxCentral. And you were certainly ahead of the curve looking at SDN and SD-WAN. Just give me your thoughts on the state of the SD-WAN industry now, particularly with everything that’s happened with the pandemic.
Roy:
Yes, that SD-WAN term. So when we started covering SD-WAN, there was still a debate as to what SD-WAN meant, and there was actually a competing definition for SD-WAN and there was essentially the SDN-controlled wide area network. So the use of SDN technologies for interconnects and the bandwidth calendaring and all the cool features that you could get by applying SDN to the WAN, was what the SD-WAN could have meant. But instead it’s come to mean what it is today, which is the enterprise edge as the series of technologies that control the enterprise edge connections – the WAN, the enterprise WAN the lot
So that that was pretty early on and it’s evolved since, and there’s still somewhere in the 60-100 players, obviously probably 10 to 15 that are interesting, and I would say that where we’re seeing right now with SD-WAN today is a couple of elements.
SD-WAN has evolved itself as well. And one of the things that is pretty popular right now, because Gartner coined a term, the SASE right? And what Gardner did with SASE, it was just as well known, the term now is to combine essentially SD-WAN with a whole bunch of other edge technologies within the enterprise. A lot of those are all security capabilities. And then by doing that created an umbrella term that included SD-WAN, but taking a much more cloud-first approach to it.
So what we’re seeing is a couple of things with SD-WAN. First is, there are some branch focused SD-WAN companies that are struggling slightly. When COVID hit with the pandemic, everyone ran away from the offices, right? And so you had a bunch of branches and headquarters that are very lightly staffed today. And so the need and the urgency to turn on SD-WAN in some of those places slowed down. But I think that will pick up.
And instead, what happened is that the SD-WAN players that were cloud-first and more focused on SASE are doing very well. I have talked to some of those and they’ve seen amazing growth in their sign-ons during the last couple of months. I mean, it’s quite compelling, right? If you have a solution that’s software centric that you can enable for your employees working from anywhere, working from home, that gives them secure access to the internet in compliance with corporate policies, definitely quite useful. Plus, some of those offerings provide you with a quick on-ramp to the internet and a private internet backbone that gives you fast access to SaaS services, right? Your Salesforce, your Dropbox, your box.
And so there was quite a compelling capability. And so those vendors in fact have done very well. And my expectation is that as a vaccine hopefully becomes available or viable in the next six to 18 months, they will see a shift to hybrid model. So you see a mix of work from home, some work from anywhere and some will head back to the office. I think many of us are realizing sort of two things. One is to how some things remarkably can be done remotely and many things as well need to be done more effectively in person. So I think we’ll see that hybrid model.
So in that situation for SD-WAN vendors, I think the cloud centric approach is here to stay. I don’t see a change in that. And SD-WAN will evolve along those lines. But along with that, the trends that we see, which is beyond the cloud first, I would say security centric, the ability of SD-WAN to reach into the branch, so SD branch, adding mobile support, IOT support multi-cloud support. I think those will not change. Those are the key evolutionary areas for SD-WAN and SaaS and that will continue.
Steve:
You know, it’s funny, we’ve been talking about hybrid for years. Never thought it would be applied to two days in the office (laughs) two days working from home, but that seems to be the way things are going and-
Roy:
Yes. It’s redefinition of hybrid, thanks to a COVID-19 exactly.
Steve:
Spoken like a true analyst.
Roy:
(laughs).
Steve:
The other thing it tells me is I’m glad I didn’t go into commercial real estate as a career. I think IT is the place to be.
Roy:
For a while, people were looking at networking, that’s sort of pretty much done and not exciting. And then SDN came along and now it’s pretty exciting and all that. And I think now with the pandemic, I think a huge realization that telecommunications is critical. It’s really important. And so it’s good news for network engineers. It’s a good thing for us.
Steve:
Absolutely. Yep. I think the importance of the network is definitely coming to the fore. So in your role at AvidThink, obviously you pay attention to what’s happening now, but I know a large part of what you do is look out into the future. So from an infrastructure point of view, what are the changes you see coming over the next few years?
Roy:
I’ll start with the easy part, which is the physical portion of it and then we’ll go from there up the stack. I think as we get more sophisticated with application and data distribution and orchestration, and as network bandwidth to the edge increases right across a wire line, wireless; with all the efforts around fiber densification, right? So you’ve got 5G, you’ve got all these other elements of connectivity that maybe low earth orbit satellites coming. My expectation is that compute will be more distributed, right? So compute and storage will be more distributed and there’ll be multiple locations and you want to call it the edge, if you want to call it the distributed cloud. No matter what you call that, connectivity’s pretty much getting everywhere. And the speed of that connectivity is increasing, and so the capabilities of what you can do with that sort of matrix, I think will increase.
And in many ways I think the same thing that has happened on enterprise campuses which for the most part move to wireless. You very seldom plug into an RJ 45, (laughs) at a desktop workstation type approach. You take your laptop and you move around. So enterprise campuses have moved to wireless. And I think we’ll see something similar in many cases on the last mile side of things as well.
And similarly I think for a lot of industrial applications, we’ll also see a transition from wired to wireless. And so what was Industrial Ethernet potentially could be served by wireless technologies, particularly mobile technology since themselves in a private LTE, private 5G, and especially in the US with CBRS and the new spectrum models. I think we’ll see that coming sort of at the connectivity that fiscal layer. Slightly above that, I think as a result of that infrastructure topology change, then we’ll see this need for distributed compute and storage infrastructure wise to go everywhere and you have to connect that.
So from a networking perspective, you have to have some kind of secure fabric throughout that provides you with the visibility, that provides you with obviously the connectivity, but also the security across all these things, right? The ability to manage QoS, the ability to troubleshoot. So I see that secure access enterprise access layer across all these locations as being one of the key things that we’ll be focusing on. And at AvidThink we made up a term, just to make fun of it, we called it FUN, which is the Fabric for Universal Networking. So we could call it universal networking fabric, but UNF didn’t quite have the same impact! But I think that layer becomes very important and I think SAE and SD-WAN and ZTNA – zero trust network access -and all these things all fall into that category. So I think that part is critical.
And then beyond that, you have obviously compute and storage. And so the infrastructure technologies underlying that will be a lot of orchestration, right? So how do you orchestrate workloads? Where do you place your workloads? How do you break your workloads up, in terms of application and distribute them the right way? What kind of services should you have in those locations themselves? You know, obviously compute and storage, but beyond that upper layer stuff, in terms of telemetry and logging, in terms of database technologies, in terms of AI, ML, I see that evolution in terms of distributed compute.
So if you take Amazon and Azure or Google, those capabilities, I think will end up getting distributed everywhere. And there’ll be a lot more focus on what runs where, so placing workloads, placing portion of workloads, orchestrating them and enabling the overall system to be resilient. I think that’s what I do see coming.
Steve:
So the main thing I got out of that is that you’re trying to bring the fun back into networking, (laughs) is that right? So that, that was Foundation Underlying the Network?
Roy:
I think that’s a foundation. I think that the fun is what sits on top of the network. It’s where, if you go up one layer of abstraction, you get to have fun.
Steve:
I like it. So, right at the end you mentioned the word resilience, and this is the network resilience podcast. Maybe you can just expand on that a little bit in terms of how you see that definition of network resilience developing.
Roy:
I’ll actually probably take a layman’s definition of it in terms of network resilience. And I’ll define it simply as the ability to ensure that your network infrastructure is able to stay up no matter what. So it just stays up. And that’s the ability to function in the face of adversity, right? So whether your network is facing fiscal challenges like natural disasters taking down your network or fires burning up that in the ground fiber, things like that. Or, it, it could be hardware failure of your devices, hardware does fail. Or perhaps it could be not hardware related, but it could be just an overlooked condition. It’s just too much traffic. Can the network stay up in, in light of too much traffic? Or software failures. The software that we put on those network devices do fail.
And sometimes, no matter how hard you try, you get into a weird situation with your software and it’s got to be restarted. Or even configuration failures, right? So the human failures, or whether it’s an immediate failure upon a configuration, that immediate mistake, or inadvertent mistake, you know. You put some configuration in place that doesn’t trigger until some weird set of conditions happens. And then suddenly traffic doesn’t flow.
So, I think the goal of the network is to be able to be as reliable as possible, but sometimes failure happens. And so the ability to recover quickly to a good known state as fast as possible, I think that’s important and I view it as resilience.
You know that failure will happen and you obviously want your network to be reliable. So you do want network reliability, but at the end of the day, you know that bad things happen. And when it happens, you need to recover quickly and that is network resilience.
Steve:
That makes sense. As we’re obviously seeing a lot more being pushed out to the edge, are you seeing that drive a change in how network resilience is considered by enterprises?
Roy:
Yes. I think as people are pushing more and more things out to the edge, there is really a concept of compute or server resilience, right? The ability to, to try to get systems up. And the way we architect software today is to actually plan for failure. So the applications stay up no matter what, if you look at some of the architectural changes on the application side with the use of microservices, with the use of containers, and to try to make things less stateful, to contain state in a constrained environment that you can control, you can replicate, you can make sure it stays up.
So I’m seeing those changes, obviously on the compute side. And I think on the network side, we’ll see the same. We’ll see a realization that as you push things out to the edge that you have to account for the fact that things will fail and you need to be able to recover. Obviously you need visibility in those failures first and foremost. But after that happens, you need a fast way to recover as well. So I do see enterprises starting to pay attention to that more and more. And with COVID-19, there’s a realization that sometimes you don’t have hands locally and remote hands have to do it. And if you can automate that, if you can detect that, if you keep it up, it’s even better.
Steve:
So, there were a couple of phrases you used in there that really screamed NetOps. You mentioned containers and remote hands and automation. How do you see NetOps changing the way networks are managed?
Roy:
For me, I used to get down on the console on a CLI. You type, the first thing you did on a Cisco thing was you go in there and you say, enable passwords and the first thing you do is write terminal. “wr space t” right? So it’s shortened, the config running across, and then you go in and change it. And that was the way we managed networks. And it’s a one-to-one situation. And that doesn’t work at a scale we’re talking about across the locations we’re talking about.
I think what’s happening on a network operation side is automation. The ability to scale operations and gain efficiencies, right? So the first thing is automate the things you are doing by hand, but beyond that, you want to manage your network infrastructure as code, right? So the same thing as we saw on the cloud side of things, with heat templates and the like bringing up an entire application, across compute and storage. We need the same thing on the network side to manage the network infrastructure as code templatize them.
And then beyond that, understanding that networks are complex and there’s a lot of variables, especially going forward. It may have to be simplified even further to take an intent based approach and say, look, fundamentally I want to connect these workloads in the following ways and be compliant and here are your constraints. Go do it for me. And there should be sufficient intelligence on the system to be able to do that. And so I think I classified that whole group of capabilities as NetOps. And I think eventually, part of NetOps will be the use of telemetry feedback loops and to use that, to start building AI assist capabilities within that that realm as well.
Steve:
So the way you talk about that suggests that the skillset for a typical network engineer is going to need to change to adapt to that. Any thoughts on, or are you seeing some of that happening already?
Roy:
I think I would say that I wouldn’t say we’re slightly behind on the networking side, because I started my life as a network engineer, but I would say that very often we do look to the compute side to see what things are happening, then we adapt best practices. And sometimes they’re relevant, sometimes they’re not. In many cases, they are. So if you look at what we did in networking, we looked at compute. Compute went virtual, storage went virtual and we’re like, Oh yeah, maybe the network can go virtual as well. So we copied that. We looked at DevOps and we say, hey, maybe NetOps on that DevOps may be a thing. And we are on the journey to make that a reality as well.
And on that NetOps network resilience, I think we can take a look at something that Google popularized called Site Reliability Engineering. So this was back in the early 2000s. And this was even before DevOps. And what Google was trying to do was to make their large scale infrastructure more reliable. And so it started out being sort of an operations role. And then they realized that if you put engineers in it, that they could automate it for themselves. So the goal obviously was to code yourself out of the equation, essentially. Because good engineers tend to want to be efficient.
I won’t use the word lazy, some people use that. They want to be efficient with the time. (laughs). And so the goal is to automate as much as you can, using code. And so this concept of a site reliability engineering SRE became a full fledged domain in and of itself within IT. And its important role at all the major hyperscalers and companies now do it, and so, it’s basically the ability to use a platform, to use automation, to use a sort of intent based framework or a config based or template framework to drive reliability.
And obviously we could use the same thing on the resiliency side as well. So SRT- SRE teams are responsible in general for availability, reducing latency, the overall performance efficiency, change management, monitoring, all those things, with regard to a site. And I think there could be the same role for Network Resilience engineers. So the evolution of NetOps, if you will, who perhaps saw it as network operations to begin with, but by using coding and automation and software to improve first the reliability and secondly, the resiliency of the network infrastructure.
I see the same thing. So I think those things will happen going beyond automation, infrastructure, or network infrastructure as code, template based deployments, and then intent based, network configuration, and eventually, AI assisted? So that’s the evolution I see.
Steve:
That’s an interesting trend. So you’re seeing it move from a DevOps team to then adding a Site Reliability team. And then you think maybe beyond that, it’ll be network resilience, perhaps to focus more on the broader distributed network and then still a layer of network engineers to do the day-to-day work?
Roy:
I would say probably it wouldn’t be the simple day-to-day, but obviously that you have ongoing troubleshooting. But I think that the ratio of network engineers to network elements will change dramatically by orders of magnitude. And so it’d be assisted. So yes, you probably will still need the network engineers to come in and help troubleshoot. But I think the vast majority of the capabilities and the work eventually could be automated, but you will need… The human eye does a lot of things that are still hard to train AI’s to do. And I would view it as sort of human assisted. So the hard problems are human assisted, but resiliency, some of those components, I think could be automated to say, look if this fails and that fails, then take this action or take that action.
Or the system could learn. We’re seeing that with ML and machine learning systems. In fact, as the network goes down, they see the network engineer, the NetOps engineer, take the following steps. And over time it’ll, it’ll learn to figure out it says, Oh, if that goes down, then I do this. Or if that goes down, then I do this. So I think that there’s going to be that that ongoing evolution over the next couple of years.
Steve:
And that lines up with the idea that networks are becoming more complex. You obviously need more complex tools and organizations to manage them. So that seems to be heading in the right direction.
Roy:
Correct.
Steve:
Just changing tacks here, a little bit. Part of the goal of the Network Resilience Podcast is to highlight the value of the network engineering community. So just curious, is there anyone in your past – a mentor or an influencer that you’d like to give a hat tip to and raise them up a little?
Roy:
On the network engineering side there isn’t one person in particular. I’ve worked with a lot of great people over the years. But I would say that on the analyst side, interestingly enough there is someone I do respect and we try to run on principles that are similar to his. There’s a company called Infonetics Research that’s part of IHS Markit. Very famous, very large company today.
The founder of Infonetics was a guy called Michael Howard. And he was a very well-known analyst in the telecoms and the networking industry. And he was great because he always tried to find and dig through all the fluff and to try to get to the heart of things. And he was able to do so in a very nice way. His approach was always very pleasant, very polite, very thoughtful. I think he was one of the greatest analysts that we had. I would see him at all the different trade shows and talk to him. And he was always very kind and I think that’s the same way we run our practice here. He was well-known in networking. And I think we aspire to carry on that same culture, that same tradition, that he had.
Steve:
Very good. Thanks for sharing that. So I know that AvidThink is producing a lot of good material. It’s always top of my reading list. You mentioned in our call prior to this, that you are working on a couple of new resource sites for SD-WAN and the edge. Can you just give us a little background on that?
Roy:
Yes, we are. AvidThink is primarily research and we’ve partnered with Jim Carroll a well-known publisher at Converge! Network Digest. He’s been running a newsletter for the last 20 years. It’s quite well-known in the networking industry as well. And together we’ve we put up a resource site called NextGenInfra.io. So that’s next generation infrastructure, but obviously we shortened it. So it’s NextGenInfra.io. And on that site, we try to cover key technology areas across infrastructure technologies. We have interviews with well-known luminaries and thought leaders in the space.
And, we’re launching the 2020 edition of our SD-WAN and SASE site in Q4 this year. And so if you’d like to get a flavor for the type of research and the content that we have, go to NextGenInfra.io and check out some of the cool resource sites already up there, download the report and we’ll be sure to let you know when the SD-WAN and SASE resource site is up, and we’re definitely looking forward to it. It’s been a lot of change in the last year and pretty exciting space for sure.
Steve:
Perfect. And we’ll put those links in the show notes for anyone that wants to go there and take a look at that. Any other resources Roy – outside of AvidThink that you find useful and you think you listeners to the podcast might find a good resource as well?
Roy:
I go to the mainstays for, for my news. So the usual suspects, right? Fierce Wireless, Fierce Telecom, Light Reading, sometimes RCR wireless and… And on the cloud stuff, I go to New Stack and then of course I visit SDxCentral, certainly. And then for podcasts, I actually like Greg Ferro and Ethan Banks. We’ve had lots of chat over the years. See them less because there’s no conventions and conferences. But, Greg and Ethan always do a good job and, and the rest of the folks over there at Packet Pushers do a good job.
And finally, we’ve collaborated with Stephen Foskett in the past. And he runs a good operation with Tech Field Day. There’s always good content there that I like to check out. So those are the places I tend to go to on a regular basis.
Steve:
Perfect. Thank you. I’m sure that’ll help some people. I agree, I’m a big fan of Tech Field Day. I’ve been involved in some of those-
Roy:
Yes. Stephen and team do a good job of covering very pertinent content.
Steve
So before we wrap up here, if people want to know more about AvidThink, where would they go for that? I’m, I’m assuming it’s AvidThink.com. Is that right?
Roy:
It is AvidThink.com. It’ A-V-I-D-T-H-I-N-K one word.com. Or you can find me on Twitter @Wireroy, W-I-R-E, wire, like the wire, Roy, just my first name. So, check us out, download a report. And, if you have any comments, we are always open to hearing from our readers. You can always reach us at research@avidthink.com. And we’ll get back to you within a day usually.
Steve:
Well, perfect. Roy, I’d like to thank you again for taking part in Living on The Edge, the Network Resilience Podcast, and all of the links that Roy mentioned will be in the show notes. And I would encourage you to reach out to Roy and, and have a conversation with him. He’s always a good guy to talk to. So thanks very much Roy, and we’ll talk to you soon.
Roy:
You’re very welcome Steve, and enjoyed the conversation as always.
Steve:
You’ve been listening to Living on The Edge, the Network Resilience Podcast from Opengear. To add resilience to your network in data centers and out to the edge, visit opengear.com.
The ‘Engine Room’ at PayPal; Site Operations and the Role of SRE
Transcript
Transcript: Living on the Edge Podcast with TJ Gibson of PayPal
Steve Cummins (00:00):
TJ Gibson is the director of site operations at PayPal. In his 14 years there, TJ has worked in a number of technical roles and currently runs PayPal’s network command center. So TJ, I saw one of your LinkedIn posts that you said a big part of your job is talking. So I guess podcasts is a natural outlet for you. Thanks for talking to us on the Living on the Edge podcast.
TJ Gibson (00:27):
Absolutely. Thank you so much for having me.
Steve Cummins (00:30):
Great. So first thing is, there’s a lot of things I think we can dig into. Site reliability engineering, I think, is something that you’re deep into. And I really want to get into that, but before we dive in, just give me a rundown of how the IT organization is set up at PayPal.
TJ Gibson (00:49):
I mean, as anybody probably imagined PayPal is a very large organization, but my organization, specifically the organization I belong to, I should say, is called site reliability and cloud engineering. And it includes everything you would traditionally see in sort of a legacy infrastructure and operations organization, as well as some platform measurement capabilities. My specific organization there is sort of incident response, network operations, site reliability monitoring and alerting and response. And then we also have a function called embedded SRE. That really is maybe the most closely thing aligned to a pure SRE role within that organization. But it’s an organization of about 600 people today that it really has their fingers in everything. I think my boss likes to refer to it as the engine room of PayPal. It’s where all of the capabilities come from, that our products really leverage to deliver services to our customers.
Steve Cummins (01:43):
Well, that’s great. And a lot of us use PayPal a lot of the time and as with everything we’re never happy when it’s not working. So I guess it’s thanks to you and the other 600 folks in your group that means we’re never sitting there and cursing at the PayPal app. So, let’s talk about this site reliability engineering. And I think, Google are often credited with being the ones that really did a lot of the early work and launched the idea of it, but I’m sure it means different things in different organizations. So what does SRE mean at PayPal and how has that changed over the last few years?
TJ Gibson (02:21):
That’s a big question. I would say that SRE at PayPal really started before SRE was really a term that we were throwing around at the industry. I think in a lot of ways, the early days of it was almost looked down upon by traditional technologists, right? They looked at it like a bug fixing team or like somebody that was really just coming in to clean up some messes somewhere and as Google kind of put their thoughts into words and started to really define this as a niche within the industry is when we said, «Hey, there’s so much overlap with what we’re already doing. Let’s look at this framework, let’s look at this way that they’re defining this role and find out how do we squeeze the maximum amount of value out of it.» And we’ve really seen it grow from that point forward.
TJ Gibson (03:02):
Again, I think the way it’s structured today has really grown beyond what traditional or pure SRE is. But we’ve really seen this conglomeration, I guess, or this aggregation of some of the things that PayPal needed, specifically. Some of the things in the industry that were really coming along in terms of technology and resiliency, and then bringing this framework of site reliability engineering as a practice, and really kind of put those things together to deliver what we’re delivering today. And really when I think about our mission, it’s not just providing these capabilities from an infrastructure or a platform perspective, but it’s really ensuring that all of the products that we deliver and all of the capabilities that we expose to customers have this reliability, this resiliency, this fault tolerance, this usability kind of baked into it from the beginning. Much like, I think, the industry 10 or 15 years ago came around to the idea of information security and really that became a niche practice and still is a niche practice, but it’s much more just a core element of a lot of products and services that people are delivering today.
Steve Cummins (04:07):
So do you think that that’s one of the defining things of SRE? Is this idea that it’s a holistic approach. It’s not looking at one piece of the operation or one location, but really looking at the whole networking ecosystem and make sure it’s covered sort of from A through Z.
TJ Gibson (04:25):
Yeah. I think the way that we tend to talk about it really is from a customer perspective and everything that a customer would expect from our products and services operate the way that they intended to be. I don’t think that it’s a niche in the way that we would think about security or networking or application development. But I do think that it’s niche in the way that it brings the sort of core skillsets of each of those, or at least the core awareness of each of those domains and brings it under the umbrella and provides this lens of resiliency and operability and scalability kind of to the way that these things come together. I don’t know if that was helpful or if that was a little bit too ambiguous.
Steve Cummins (05:03):
No, that makes sense. You mentioned an embedded SRE function and I’m curious, are you talking about that you have folks that are sort of out in the various operating units that are reporting back into your group or is that something else?
TJ Gibson (05:21):
No, I mean, it’s essentially that it is a more of a dotted line from the SRE organization out to these various domains. I think a lot of places when they implement SRE as a specific discipline will look for filling a role within an engineering team. A lot of times when you talk about an agile team, you’ll have your software developers, your product manager and so on. And I think a lot of organizations will bring that site reliability at that level. The way that PayPal has really approached this is more from a centralized aspect, but building these dotted lines between dedicated teams who have the awareness, not just of the domain that they’re embedded but the business that they’re embedded with.
TJ Gibson (05:58):
So within our payments organization or within our identity organization and really understanding how their products and their platforms are put together and bringing that SRE discipline or that SRE mindset to help them holistically figure out how do we make this thing the best it can be? How do we make it a great citizen within the application, so that as those handoffs upstream and downstream are happening, that all of this reliability and operability components are being accounted for.
Steve Cummins (06:24):
Got it. That makes a lot of sense. So in terms of security, which you mentioned is sort of a similar evolution, is security interwoven with SRE or do you still see that as a separate entity?
TJ Gibson (06:37):
I don’t know that I would say it’s woven into SRE. I think it’s become more a part of everything we do. So yes, it’s a part of SRE, but it’s not something that SRE is bringing to the table. It’s something that we hold ourselves accountable to. It’s something that our customers and our business holders hold us accountable for, but really it comes down to the security aspect of it being interwoven to everything we do. if I could kind of project this forward in terms of SRE, I think where I see this progressing in the coming years is that we start to see a lot of these core things today that we would say belong to site reliability engineering. We will see them adopted and integrated with the ways people work when they’re developing products, or when they’re deploying a new network segments or new data centers.
TJ Gibson (07:26):
I think it will become more just a sort of foundational component of how we do IT, the same way that security has over time. I think we’re in a little bit of a transition period here where SRE has kind of come into its own, it’s become a mature role or discipline within the industry. And I think that will stay true as we go forward. But I think some of those things that SRE are bringing today will become part of core platforms and become part of the core workflows as opposed to always being a centralized single accountability kind of function.
Steve Cummins (07:57):
And I guess even the role that you have, although I focused in on this part of your job, which is the SRE, I mean, you really have responsibility for the overall site operations. Right. And SRE is a part of that. So, I guess it emphasizes that idea that SRE is a part of everything that you do rather than being looked at as a standalone piece of the business.
TJ Gibson (08:18):
Sure. And I think in a lot of ways before we actually started recording here, we talked a little bit about DevOps and SRE and what are these things mean and how do they play together? And when I think about my role specifically in that operation center, there’s definitely a push to a more federated accountability model. Right. And so it kind of speaks to DevOps, but I don’t know that either one of these things could really exist independently. I think they’re flavors of the same kind of thing. Right. It’s the way that we work and the way that we provide services and capabilities to our customers and making sure that we have the right mechanisms or the right levers in place to be able to respond when we need to, when something’s broken, but also to be able to plan and design for failure and to be able to plan a design for customer outcomes.
Steve Cummins (09:05):
And I think, particularly in a big organization like yourselves with many moving parts, it makes sense that it covers across it. Do you see any drivers over the next few years that’s going to change the way that SRE is implemented or you think it’s just a continuing evolution?
TJ Gibson (09:25):
I certainly think that there’s always going to be changes. I think, as we see more and more large enterprises really grab a hold of this idea of public cloud and really start to move workloads, I think I saw recently that Capital One essentially was declaring victory in their cloud journey. I think that brings an entirely new perspective on sort of large scale applications and site reliability engineering. But I also think going forward there’re things that I think we haven’t quite yet accounted for. I think machine learning and artificial intelligence is going to bring aspects to our technology stacks that we just don’t have an idea of what that means to be resilient and what that means to be operable. And how it is that we use that sort of technology most effectively, I think SRE has a role to play there as well.
TJ Gibson (10:14):
I think when we look at some of the things that SRE is bringing to the table today, in terms of frameworks and structure and accountability, I think a lot of that we will start to see baked into our applications. I think there’ll become more natural for people as we’re going forward. And so that’s going to, I think, create an opportunity for SRE to, again, maybe step up and up level their viewpoints, similar to maybe how information security practitioners have been able to up-level and make a tighter connection to the policy or the regulatory obligations. I think SREs will be able to continue to look for those opportunities to step up and bring sort of business aspects further down into the stack. And I know that’s a little bit fluffy, so I’m happy to kind of call out some context there if we need to. Okay.
Steve Cummins (11:00):
Hey, I think when you’re talking about trends for the future, if you’re not being fluffy, then you’re fooling yourself. Right. Because who knows what’s coming up, but I think some of the trends you talk about, machine learning and AI, we all know it’s going to have a big impact. And I think it’s just that question mark of how quickly and in what ways, but it’s a fair point, SRE is going to have to adapt to as everything else is along with that. So just shifting gears a little bit. So I’m always curious about career paths and how people get to where they are. So I know you started out in the Air Force, you worked in a couple of networking roles in some other companies, and now you’ve been at PayPal for a number of years, and you’ve talked to a lot of technologists in that time, as you mentioned to me, and you have this idea of how the three phases in a technical career. So maybe you could just sort of talk through that a little bit.
TJ Gibson (11:57):
Yeah. And I wouldn’t say that it’s really just limited to the technology career field, but that’s obviously where my experience is. And the way I try to talk to my folks about it is, and I think early on in your career, the value that the business perceives from you as an individual, from you as a technologist, really boils down to how much you know. Like what do you know? And I think the deeper you know a particular technology or domain area, the more technology or domain areas you know, the more your value is to the organization. I think you hit a point probably somewhere in that five to 10 year point in your career. And it’s obviously very different for everybody, but at some point if you could call it a journeyman, I think you hit a place where it becomes about who you know. It’s not possible to know the depth that you have to, it’s not possible to have the breadth that you need, in order to deliver the outcomes you’re being asked to deliver.
TJ Gibson (12:50):
And so the way that you provide value to the organization becomes much more about how do you bring people together? How do you find the right answers and the right resources within the organization? And I think for the most part, technologists do this pretty well. I think it makes sense. I think it’s a pretty natural evolution. I think where a lot of people tend to get tripped up is in that kind of third step, but it becomes more about who knows you. And yeah, there’s an element of politics there, every place no matter how apolitical they claim to be, there’s always politics, but I don’t think that’s the core of it. I think it’s really about demonstrating value. And so couple of things I try to tell my people are, what is it that keeps your boss up at night?
TJ Gibson (13:28):
Those are the things that you should be looking for solutions for. Those are the things that should also be keeping you up at night. You need to be looking for, how do you bring your talents, your experience, your responsibilities to bear on that problem statement, to help solve it. And I think that’s where a lot of people tend to struggle with wrapping their heads around it. It’s not that it’s incredibly difficult to do, but it’s certainly a mind shift. And so when I say, who knows you it’s about who sees you as the problem solver who sees you as the one that’s going to bring your experiences and skillsets to bear on my problem and understand the context quickly, get to relevance quickly and be able to help me find solutions that technology will solve for my particular business problem. And of course, we’re doing all of these things throughout our career.
TJ Gibson (14:12):
But when I think where I see people really kind of get stuck in a rut, that 10, 12, 15 year mark in their career, is because they’re struggling, maybe I shouldn’t say they’re struggling, where they really start to have challenges is when they start to get uncomfortable. When they start to have problems solving business problems or connecting with their peers that are stakeholders. They tend to fall back on the things that have worked for them in the past. And so they might go out and say, I’ve been in the career for 10 years or 15 years, the technology has moved so fast and I’ve been thinking at this higher level, my problem is I need to go learn the latest and greatest.
TJ Gibson (14:49):
I need to go dive in deeper into whatever technology stack is in front of me. And that is always valuable, but that’s not the only answer. I think what the business is looking for people, technologists specifically, as they reach that higher level in their career is more of a connection back to how technology solves those business problems. Where very early in your career, it’s very much about how to implement a particular solution that’s been given to you or that has been defined.
Steve Cummins (15:16):
Yeah, it’s very true. We tend to focus on the technical skills, right. But I think as you move up in an organization and you sort of broaden your influence, it really does come down to being known, knowing how to get things done. I mean, for me personally, this always flags up. When I move companies, as I’ve done in the past and you’re in a new job, and you realize at that point, how important it was to you in your previous role, because you knew everybody and you knew how to get things done and people knew who you were and if you change companies or organizations, you often have to relearn that. So I think the three phrases you describe make a lot of sense.
TJ Gibson (15:57):
Yeah. And I think the important thing to call out is that it’s not that you’re leaving the technology career path, right? It’s not the technology becomes secondary to the value that you’re bringing to the organization. It’s about being able to layer on that relationship skill set, that business understanding skillset, that translation skillset in a lot of cases to get from business outcomes into technology solutions. And so it’s not about leaving technology behind or ignoring it or not being hands on keyboard anymore. It’s about being able to make stronger connections back to the organization, back to where your customers are and back to where the value that you’re delivering to them is coming from.
Steve Cummins (16:37):
Yeah, for sure. I think that all makes sense. So having just said how important it is to look at the non-technical side of it, I am curious about the technical training side of things. So in terms of that sort of technical… there’s a number of certification path, like I guess CCIE is sort of the most well-known one. And recently Cisco added a DevOps section to it or DevNet section to it. I’m not aware of anything similar that focuses on this SRE or a liability or even site operations part of it. Is there something out there that a certification path that people would follow or is that something that you think needs to be worked on?
TJ Gibson (17:25):
There are some folks that are offering different certification paths for SRE, but I haven’t seen anything really rise to the top as kind of an industry standard. And I think if I look at kind of how the industry is handling the learning and the training around SRE, USENIX has every year a conference they call SREcon. And I think if you look at some of the agendas or the seminar schedules, excuse me, schedules for these events, these conferences, you’ll see the diversity there, right? You can have some very deep tracks on how to use machine learning to bring better insights from your observability platform. Some very deep tracks about how do we build networks for resilience and how do we handle this massive global scale? How do we deal with hybrid cloud?
TJ Gibson (18:10):
But you’ll also hear a lot of higher level things. How do we do problem management? How do we do root cause analysis? How do we actually understand where our customers are coming from? How do we determine business logic failures differently from systemic technology types of failures? So I think in a lot of ways, the industry is still trying to figure out what SRE looks like. I think there’s still a lot of definition of discovery that’s happening. It’s much more solid than it was in years past. But I think, again, even if you look at some of those conference schedules year over year, you will see kind of the focusing or the narrowing down of their scope or the solidifying of the way that they’re viewing that particular industry career field. So I think when it comes to SRE, if that was of interest to some particular technologists, I don’t know that I could point you in a particular direction.
TJ Gibson (18:58):
I think what I would say is breadth at this point in time, I think is extremely important. I don’t think it’s enough to have only an application development background or only a networking background and be able to step cleanly into an SRE career field and be successful day one. I think you really have to understand all of the sort of constituent parts and how they play together towards the business outcome of reliability, of operability, of performance. And so I think what I would suggest is go get some breadth, right? And this is happening a lot in our data centers already. We’re already looking at how do we build our on-prem data centers to be more abstracted, to have the hardware, the physical infrastructure more abstracted for the users, very similar to how you would see an application deployed in AWS.
TJ Gibson (19:46):
So I think if you can kind of start to spread out a little bit and start to look for how can I bring in some of these elements of development and some of these elements of business awareness and some of these elements of observability and response. I think if you can bring those things into your purview and into your skillset, that’s where you really start to have kind of the building blocks for being a good site reliability engineer. And I think the questions that I would be asking for, the opportunities I would be looking for internally, is how to leverage all of these things together to deliver reliability as a service or operability as a service or observability as a service kind of thing. I know that’s very fluffy, but again, I think the industry is, at least this particular career field, is still in a bit of early stages.
Steve Cummins (20:33):
I actually, I think it’s spot on. The pendulum the last couple of years seems to have swung back a little bit. Everybody wanted to be a specialist in something right. Wanted to be very niche-y. And the word guru and ninja was used far too often for people. But it does seem as though the pendulum has swung back. And there’s an understanding of the value of a little more of a generalist approach where you can bring in parts of different skillsets or different backgrounds to combine them and get something done. And I think the world of SRE is probably a perfect situation when that make sense.
TJ Gibson (21:13):
Yeah. And I don’t know if I would go so far as to say SRE is really a generalist career field, but I do think that having that generalized background that’s really the context you need to be successful in SRE. It’s not enough to understand how to build the most reliable, most resilient most scalable network, if the application on top of it doesn’t know how to consume and use that benefit. And so really understanding at least at a base level, how all of these things come together and where the strengths of one particular domain compensates for the weaknesses in another domain. So I think you have to have that generalist mindset, even though SRE, I think, is a very specialized skill set or a very specialized role. So maybe in a way it’s kind of a mix of both of those worlds and it survives those massive pendulum swings over time. Again, maybe the correlation back to information security.
Steve Cummins (22:05):
There’s a really interesting book called Range, I can’t remember who wrote it, but I’ll put it in the show notes, that talks about exactly this. And the point is get a broad background first because it’ll inform on anything you do in the future. And it will also let which is the area that you really should focus on, whether it’s something you good at or something you have an interesting or a passion for. As opposed to specializing too soon and then realizing you can’t broaden out. So it’s an interesting book I think might be worth digging further into that topic. So you mentioned resilience a couple of times and an open gear that’s really our focus is this idea of network resilience. So as someone who really spends their days, I would imagine thinking about the reliability of the operations, what does the phrase network resilience mean to you?
TJ Gibson (22:57):
I think to me, it really means that we’re capable of surviving faults and that’s an overly simplistic answer, but really it comes down to our ability to meet the business needs to meet the customer expectations in a way that is efficient and effective and allows us to continue to innovate. And then there’s a lot wrapped in that. But really to me, that’s really kind of what it comes down to is just being able to respond and react and absorb and grow to what we need. I think sort of the anti-pattern there would be a very specialized I think about the olden days of mainframes and the AS400 sitting in the basement that I’m sure a lot of banks still have sitting around, you build this thing that does one thing so well that it really can’t evolve and grow with the needs of the business or with technology as they continue. So to me, it comes down to flexibility maybe is the best way that I can describe it.
Steve Cummins (23:55):
I think you may get the award for the shortest definition of network resilience we’ve had on this podcast, surviving fault. I mean, it says it all. I like it. Makes a lot of sense.
TJ Gibson (24:06):
Like I said, maybe overly simplistic and not what you were driving at. Maybe that’ll drop my stock value a little bit.
Steve Cummins (24:12):
No, because then like old good interview guests, you then went into an explanation of what you meant by those three words. So that’s spot on. I like that.
I’ve got to believe, in your role, you have a hundred “oh crap” stories where stuff went wrong and it’s kind of why this podcast called Living on the Edge. Right. Because everybody has those stories of living on the edge. So do you have one that you’d like to share with us?
TJ Gibson (24:40):
Yeah. And I’ll set it up a little bit. I was actually putting quite a lot of thought of this. And like you said, there are many, many, many examples. I had some advice early on in my career when I was doing some consulting and I was very nervous about standing up in front of a boardroom full of executives and trying to tell them where their vulnerabilities are. Not so much that I didn’t know or it didn’t have the data to back up what I was saying, but I just had no idea where the questions were going to come from what the angles and the agendas were of the people in the room. And so I was really kind of stressing out in this big readout that we were going to do. And one of my colleagues sat down and he said, «Look, consulting is like 10% technical and like 90% people.»
TJ Gibson (25:21):
The more I’ve kind of internalized that and I’ve grown in my career, I feel that’s pretty broadly true for technology in general. So a lot of my sort of oh oh moments or my hairy late nights really come down to people things kind of mixed with technology. So the one that comes to mind and maybe I’ll get a little bit of trouble for even sharing this story, but was actually in the Air Force. I had my boss at the time had pushed a configuration file to every machine on our network, relatively small network, but very geographically distributed. So 180 nodes or so spread across 40 countries. That file set the same IP address on every device on the network. And this is in the mid ’90s, so a lot of our automation that we take for granted today just wasn’t there. It just did not exist.
TJ Gibson (26:08):
And so spending three days trying to talk pilots and people loading airplanes all over the world into how to change the IP address to something that matched, what was, we’re going to work on their local network. That to me was one of the hairiest moments, not just because it was so complex and so people focused to resolve, but really just highlighted how fragile sometimes some of these things we take for granted really are a one simple human mistake and essentially shut this thing down for three days. And I think maybe the reason I bring that story out is just the irony at the end, that may resonate with a lot of your people, but my boss got a medal for fixing that problem. So I think that was kind of my funny story I wanted to bring is, we made a mistake we spent a whole lot of time trying to correct for it. And ultimately as the cause of that mistake somebody was rewarded.
Steve Cummins (27:00):
Yeah. Unfortunately that’s how life works. They forget the mistake, but just remember, oh, yeah. But hey, everybody bounced back. And let’s be honest, I guess, that’s also what we get paid for. Right? It’s not about mistakes happening. It’s about how you react to it, but it seems a shame you didn’t get the medal instead of your boss.
TJ Gibson (27:19):
Well, look, he was definitely involved as much as I was in putting things back together. And I think in a lot of ways I’ve carried that with me. I think for a long time, there was a little bit of bitterness. Darn it, you caused a problem and we had to go jump through hoops to fix it. And you got a pat on the back, but in so many ways that leads to where we are today, right? This blameless culture that we’re looking to learn, looking at every failure as an opportunity to get better. I think that maybe was an early step in that direction. Maybe I didn’t appreciate it for what it was in that moment, but there’s so much value in being able to fail miserably. And even because we screwed up, but when you can recover from that and you can learn what happens and you can look for opportunities to build automation or gates or controls that would prevent that mistake from ever happening again, that’s a win.
TJ Gibson (28:08):
The fact that we found it when we weren’t getting shot at is a tremendously great thing. The fact that my site went down last week or maybe even we took it down last week at 3:00 AM. That’s amazing because it didn’t happen during the holidays when we weren’t expecting it, we actually pushed the button. We knew exactly what happened. We’re able to fix it quickly, that kind of stuff. So I think there’s even some lessons in that kind of on the edge moment that I think we’re putting into practice 15, 20 years later in the industry and it’s making us better.
Steve Cummins (28:36):
Well, and it does put it in perspective a little bit. Right. We all think that our problems are big, but you just used that phrase. «Well, at least it didn’t happen when we were getting shot at,» which is not normally what people have to worry about. So yeah, I guess there was a life lesson than that for yah.
TJ Gibson (28:55):
A little bit, yeah.
Steve Cummins (28:55):
So talking about life lessons, I always like to give people a chance to give a shout out to somebody that’s helped them in their career. Somebody who’s influenced them or been a mentor. So anybody you’d like to recognize?
TJ Gibson (29:09):
I’ve actually got two, if that’s okay and I’ll try to be quick.
Steve Cummins (29:12):
Yeah. Go for it.
TJ Gibson (29:14):
The first one was my boss in my first people management role, it was a role that came to me through a little bit of duress, a little bit of emergency and a need in a crisis. And I had told them, I don’t know about people management. I don’t know if this is the right step for me. I don’t know if I’m going to like it. I don’t know if I’m going to be good at it, but I’m going to give it a shot. Just promise me that if I suck or I don’t like it, I can have my old job back. Yeah, yeah, sure. No problem. So I took this job and about six months into it, I went into my boss’s office frustrated and I just couldn’t, there was too much, I just couldn’t get it all done.
TJ Gibson (29:47):
And he sat me down and he gave me some of the best career advice I’ve ever had. Overly simplified, but it means a lot to me. And he said, «I’m not paying you to get to the bottom of the pile. I’m paying you to put the right things on the top.» That’s what management’s about. And so that idea that the value you see from me is in how I make decisions and how I prioritize and how I respond. That’s the value I’m driving, not in my task list, not in getting to that bottom of that pile. That’s been some of the best career advice I’ve ever got. The man’s name is Roy Santarell. And I hope at some point he gets to listen to this and know how much that’s meant to me. But I think secondly and maybe this will sound or feel a little brown nosy, but it’s actually my current boss.
TJ Gibson (30:26):
I’ve known the guy for 10, 11 years now. He’s been a cheerleader from the sidelines forever. He’s been in my direct reporting line for about the past four or five years now, but he’s really just showed me what it means to… just boundless energy. He showed me what it means to care for people. He showed me what it means to set hard expectations and challenge people, to give them the autonomy they need to be successful. Give them the support they need when they fallen down or when they’ve hit a challenge or a roadblock. And he does all of this in a way that’s productive. It’s not ever in a way that’s letting me get off the hook, right. There’s still strong accountability there. There’s still high expectations, but it’s done in this supportive way where I know that he’s got my back.
TJ Gibson (31:16):
And I think for any leader, that’s really the most important thing I could ever ask for from a boss. And I think any technologist should ask for, from a boss. Give me the autonomy to do hard things, give me the challenges that are going to help me get better and stronger and grow. But give me the support. Don’t throw me out there to fail. Don’t throw me under the bus and all of that. So [inaudible 00:31:38] as my current boss and longtime mentor is another one that I would tip my hat to.
Steve Cummins (31:45):
So both Roy and West will be very happy to hear that. Last question for you because people are always trying to work out where do I go look to learn more about whether it’s general networking or cyber liability, whatever it might be, any resources, any websites, podcasts that you would recommend?
TJ Gibson (32:05):
I wouldn’t even be able to point to one or even a handful, but what I will say is where I get the most value is from very obscure sources. And what I mean by that, the Freakonomics book had an impact on me. And it wasn’t in the things that they were talking about. It was in the way that they viewed a problem and the way that they went about finding solutions or finding insights from that problem. I think anything you can do to look for ways to think differently, to think broader, to bring a different perspective to your work. I think that’s where you really get the most value, the bits and bytes, the particular configurations, the new technologies, that stuff will just continue to evolve and change. If you have the framework, if you have the baseline, you can continue to stay on top of those things just naturally, at least in your role as those things come to you.
TJ Gibson (32:59):
But I think that unique perspective or that insight that you get from looking at things from a different angle, I think that that’s rarely where I see people shine and succeed. And if I could make just a quick plug, I would say, this is one of the big reasons why diversity is so important in the technology career field. Just because I think for too long, we’ve had a bit of a myopic view. We’ve only had a limited number of perspectives brought onto our problems. And that’s resulted in a lot of things that we probably take for granted today that in my mind are actually fundamental flaws in the way that the internet works.
TJ Gibson (33:32):
You could look at DNS, you could look at IP space, there’s a lot there that constrain us going forward and we don’t even realize it. So I think that would be my call to action, or that would be my suggestion is let the technology specific pieces just come to you as they need to, as you bump into them, as colleagues mentioned them, as you learn about them in conferences, but where you’re going to really find your success is being able to bring a unique perspective. Either from conversations with other people or from completely obscure sources that really don’t have a ton to do with technology. And that’s the best way I can non-answer your question. I hope that’s okay.
Steve Cummins (34:09):
Yeah. You should be a politician, not answering questions. I actually, I agree. And I have to say Freakonomics is one of my favorite books. I don’t know how long it is since I’ve first read it, but this idea of unintended consequences is something that often rattled around in my head of, «Okay, we’re going to do this, but what is going to happen that we never planned for. Right. And how do you be ready for it?» So, yeah, I agree with you, you have to step outside of reading just the regular stuff and bringing some broader perspectives to it. So, I’m not even going to say it’s a non-answer, I think it’s a really good answer. So I like that.
TJ Gibson (34:47):
For what it’s worth, that mindset of unintended consequences or a mindset, again I come from a security background as well, so that mindset from security of always thinking like the hacker, that’s what makes a good site reliability engineer is how is this going to bite us? How can this be better? Where are the flaws and the weaknesses in this whole flow? So, yes. I mean whether you get that from Freakonomics or you get that from colleagues, or you get that from other experiences, I don’t know that you get that exactly from industry training or industry technology learnings that are pretty typical.
Steve Cummins (35:22):
Yeah. So on that and in terms of diversity, would you hire a former hacker?
TJ Gibson (35:31):
I think it would depend upon the way in which they were communicating to me. I maybe have this flaw for a technologist that I really try to get inside the mind of people, where are they coming from? What’s driving them, what are their motivations? But I think your background really has nothing to do with who you are today. We all change. I mean, if we were held to account for things that we did when we were 17, Steve, I’m not sure how old you are, but if we had social media when we were in high school, you probably are second guessing a lot of decisions you made. So I think your background has very little to do with who you are today. And I would be looking more to assess the talent and the capabilities being brought by any particular person.
Steve Cummins (36:12):
Yeah. That’s a great point.
TJ Gibson (36:13):
Them being an ex hacker has nothing to do with it in my mind.
Steve Cummins (36:15):
No. That’s fair. And it does fit nicely with your point about diversity, right? You have to bring a lot of different pathways to really get a broad understanding of things.
TJ Gibson (36:27):
Absolutely.
Steve Cummins (36:29):
I tell you TJ, this has taken us in a couple of directions I wasn’t expecting, which is always fun for me when we’re doing these interviews. I do really appreciate you taking time to share your thoughts with us on the podcast and look forward to talking again soon. Thanks very much.
TJ Gibson (36:46):
Thank you so much. It’s been a pleasure.
Network Resilience on Campus
Schools and universities must protect their existing infrastructure to support constantly evolving compute requirements. Campus networks pose unique challenges for network teams since most span multiple buildings that may not be easy to physically access. In this webinar, we discuss how network teams on college & university campuses can deploy a smart out-of-band network to ensure resilienc
- Network challenges specific to university & college campuses
- What is Smart Out-of-Band and how does it fit as a solution?
- A Case study of the University of Siegen deploying Smart Out-of-band

Dirk Schuma
Regional Sales Manager, Northern Europe
WATCH THIS WEBINAR
Network RQ
Network RQ
Network RQ is a way of looking at all the elements of network resilience, and explaining their impact to others in the organization. It’s a set of resources and language to help you succeed in building a reliable infrastructure.
To learn more visit: https://opengear.com/resources/network-rq/
Network Resilience
Building Network Resilience
White paper: Building Network Resilience

Network Resilience: Keeping the network running at the core and out to the edge of the infrastructure, with no disruption to the customer experience in the event of human error, external issues or hardware failures.
Network outages have a direct impact on an organization’s revenue, customer retention and brand. Network resilience plays an important role in ensuring business continuity. When the network is down, money can be lost, productivity can be stunted and data security can be at risk.
Achieve true network resilience, when an organization is able to maintain services, remove points of failure and has an understanding of how to bring the network back up during a disruption.
Download this white paper to learn:
- Why network resilience is important
- How to get support from top leadership
- The most important factors in building a resilient network
The 7 Step Journey to Network Resilience
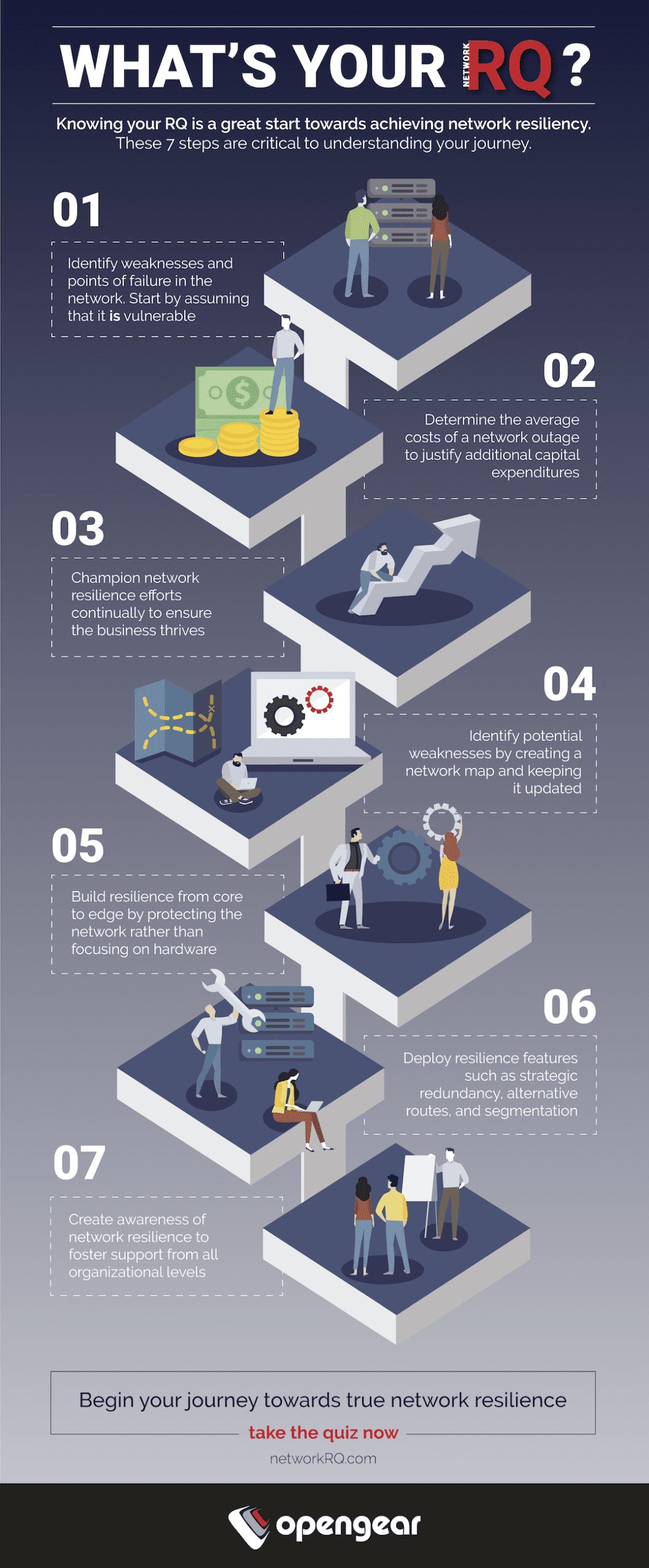
Network resilience from core to edge in financial networks
Network resilience from core to edge in financial networks
Learn how one of the top performing banks in the United States utilized Opengear smart solutions to decrease their downtime, reduce the need for site visits, and ensure compliance requirements are met.
To learn more about network resilience solutions for your financial organization, please download our whitepaper today!
Network Resilience: An Extreme Case of Remote Network Management
Network Resilience: An Extreme Case of Remote Network Management
What Does the Growth of IoT Mean for IT Infrastructure?
Railroads have a unique set of challenges when establishing network resilience, these include regulatory restrictions, safety standards and compliance. In an effort to resolve these, a Class 1 Railroad decided to approach Opengear to discuss remote network management for their organization.
Thousands of miles of track and hundreds of monitoring stations across the United States poses a challenge when connecting network devices. The railroad was losing network connectivity and flying blind when it came to scheduling, maintenance and track switches. To monitor and maintain connectivity, the organization tested Opengear’s solution for cellular out-of-band capabilities.
For 6 months, the railroad rigorously tested the ACM7004-2-LMV with built in cellular. To ensure that the devices met their requirements, could perform in extreme environments without interruptions from vibrations and was able to be easily used by network administrators, the devices network resilience capabilities were tested.
Once testing was completed, Opengear’s devices were the clear solution. The railroad deployed the Resilience Gateway at each of their key locations, resulting with over 150 units across their network. The anticipated result is to reduce truck rolls by 50%, repair connectivity in a matter of minutes and ensure network resilience.